API Design Rules
| Version | 5.0 |
| Status | Adopted |
| Publication date | 2025-09-19 |
This document is a publication of Het Normo. In the pursuit of completeness and correctness of data, we kindly request you to submit comments, additions and improvements regarding this document by raising a ticket in this repository.
Document annotations
Please find the following information here:
Changes - for all changes in this publication
Signoffs - for notification and signoffs for publication
References - for references to other publications
Dictionary - explanatory guide for terms and abbreviations
Table of contents
Introduction
The current generation of applications are realized according to a service-oriented architecture. The goal here is to increase the flexibility in service provision. The unlocking of these services is realized by web services and, for some time now, also by REST APIs.
Within the context of service-oriented architecture, the design of web services and APIs is of great importance. A poorly designed web service or API can make the development of applications that call these services unnecessarily complex. From a business perspective, a poorly designed web service or API can have a negative effect on the flexibility of business processes. On the other hand, well-designed web services and APIs can improve the development speed of applications and the flexibility of business processes. For the design and development of web services, the former NEDU TC, in close cooperation with EDSN, has drawn up the design choices for web services1. The parties in the Dutch energy market, united within the NEDU, have expressed the need to also define guidelines for the design of APIs. Commissioned by the former Technical Committee NEDU (TC), a working group has drawn up the following documents2:
- API Strategy
- API Design Rules (this document)
- API URI guidelines
The starting point for the API Design Rules is the API Strategy for the Dutch government. In addition, the energy sector-specific design rules are laid down here.
Design rules
The STD rules are the standards set by other bodies that guide the APIs designed and developed by the energy sector.
The remainder of the document contains the guidelines that have been drawn up based on best practices and lessons learned and are guiding for the APIs that are designed and developed by the energy sector. These guidelines are supplementary and/or prevailing to the API strategy for the Dutch government (ASNO).
ID STD-01
| Title | STD-01 - API strategy for the Dutch government |
|---|---|
| Strategy | When designing and developing APIs, the API strategy for the Dutch government (ASNO) is guiding. |
Open section for explanation, rationale and exception conditions
Explanation
This API strategy has been designated by Het Normo as a general starting point for designing and developing APIs. Energy sector specific design guidelines are included as additional rules.
Rationale
The Dutch government its API strategy is quite well thought out and mature. There is also the possibility that the energy sector will also adhere government APIs.
Exceptions
Not all service interactions are suitable for a REST API. When deciding to develop a REST API, consider whether a REST API is suitable for the specific purpose.
ID STD-02
| Title | STD-02 - Standardized information models for defining the API |
|---|---|
| Strategy | For the definition of the interface (the API), the standardized information models such as IEC CIM, ebIX UML Model and ebIX EFET ENTSO-E Role Model are leading for naming resources and attributes. |
Open section for explanation, rationale and exception conditions
Explanation
These standardized models are designated by the energy sector as the standard for defining assets and market processes:
- IEC Common Information Model (CIM);
- ebIX UML Model for the European Energy Market;
- OASIS Universal Business Language (UBL);
- CMF Market Model;
- ebIX EFET ENTSO-E Harmonised Electricity Market Role Model;
- NEN 5825 standard for address notation;
- BAG (Basic Registration of Addresses and Buildings). This overview of models is not finite and may be supplemented with other standardized models if required for the definition of the interface.
Rationale
By using this design guideline, the definition of the API follows the (international) standards IEC CIM and ebIX®.
Exceptions
Not every information need is covered by the standards. Own extensions of an existing standardized model are preferred (instead of inventing your own). These extensions can be returned to the working groups that maintain the standardized models.
ID 01
| Title | 01 - Interface definition language |
|---|---|
| Strategy | Definition of the interface (the API) is done in UK English. |
Open section for explanation, rationale and exception conditions
Explanation
Specifications for APIs within the energy sector and documentation within the API definition (like fields ‘description’ and ‘example’) are set in the English language. This extends to all resources and attributes.
Rationale
ASNO prescribes the use of the Dutch language (API-04). Design guideline for the energy sector for the definition of the interface is UK English (or British English) because this language is more in line with (international) standards such as IEC CIM and ebIX®.
Exceptions
Individual companies may follow their own guidelines on language usage.
Service descriptions may either be in English or in Dutch.
ID 02
| Title | 02 - Version management |
|---|---|
| Strategy | APIs are always provided with a version. |
Open section for explanation, rationale and exception conditions
Explanation
APIs are always provided with a version. Rules for versioning:
- major: Not backward compatible, therefore major impact for the service consumer;
- minor: Backward compatible, limited impact for the service consumer;
- patch: Backward compatible, no impact for the service consumer. Intended for small fixes and may be rolled out without further specific notification.
Which version characteristic is included in the naming of the API is described in the NEDU API URI guidelines 6.
Rationale
Agreements on which version(s) is/are in production and whether there is a transition period between the versions are, in contrast to the guidelines from ASNO (API Principle 4.4/API-20), not imposed as a generic guideline for the energy sector. Instead, agreements are made and recorded per API. New versions of the API and production version are supported during a transition period. The number of versions that may be in production simultaneously is limited to two (2) or as prescribed in the implementation strategy of the relevant MFF Topic.
Exceptions
None.
ID 03
| Title | 03 - Query parameter for sorting |
|---|---|
| Strategy | Use ‘_sort’ or ‘sort’ for sorting of the result set. |
Open section for explanation, rationale and exception conditions
Explanation
This is conform ASNO API-31. To prevent confusion or conflicts with resource parameters the underscore variant is favoured.
Rationale
Using a standardised parameter for sorting increases comprehensibility.
Exceptions
None.
ID 04
| Title | 04 - Query parameter for searching |
|---|---|
| Strategy | Use ‘_search’ or ‘search’ for full text searches. |
Open section for explanation, rationale and exception conditions
Explanation
This is conform ASNO API-32. To prevent confusion or conflicts with resource parameters the underscore variant is favoured.
Rationale
Using a standardised parameter for searching (full text searches) increases comprehensibility.
Exceptions
Complex searches should make use of a request payload.
ID 05
| Title | 05 - Errors and exceptions |
|---|---|
| Strategy | APIs must handle errors and exceptions uniformly and according to standards. |
Open section for explanation, rationale and exception conditions
Explanation
Error messages must be specified according to the standardized error message format of RFC-9457 (RFC 9457 - Problem Details for HTTP APIs), as prescribed in API-46 in ASNO. The following attributes are mandatory for each error message:
- type: contains a URI reference to the error type;
- title: generic title for the error type;
- status: the original HTTP status code provided by the server; The default value ‘about:blank’ may be used if no URI reference for attribute ‘type’ can be given.
Example:
{
"type": "https://datatracker.ietf.org/doc/html/rfc7231#section-6.5.3",
"title": "Forbidden"
"status": 403
}
In addition to the mandatory attributes mentioned above, RFC-9457 specifies a number of optional attributes:
- detail: additional detailed information about the error;
- instance: URI of the call that caused the error.
RFC-9457 allows the error message to be extended with context-specific attributes to send additional information in the response to the consumer. An example of this is the sending of a so-called ‘errorCode’ by the application in question, which refers to a business rule of this application that indicates why the submitted request cannot be processed.
Errors and exceptions must be handled in accordance with the following guidelines:
- The error message must be formulated abstractly and functionally so that every consumer understands it;
- The (functional) error message must be in the payload (body) of the message;
- The error message must not contain any (technical) implementation details (e.g. stack trace).
See the appendix for a detailed description of a proposed mechanism for handling errors according to RFC-9457.
Rationale
This enables consistent and clear behavior for error messages.
Exceptions
None.
05 - Errors and exceptions
ID 06
| Title | 06 - Use of ODATA |
|---|---|
| Strategy | APIs should be specified in OAS. |
Open section for explanation, rationale and exception conditions
Explanation
In principle, no support for ODATA in the NEDU API strategy.
Rationale
A detailed use case will determine which type of API is best. For APIs where datasets can be requested in many ways, ODATA is a possible option. Keep ODATA or WFS as a separate standard, do not force them in OAS/API form.
Exceptions
None.
ID 07
| Title | 07 - Definition of attributes Info object |
|---|---|
| Strategy | Every API (from OpenAPI 3.0 and higher) must be provided with an Info object with information about the API. |
Open section for explanation, rationale and exception conditions
Explanation
The following attributes must be included in the Info object:
openapi: 3.0.3
info:
title:
description:
termsOfService:
contact:
name:
email:
license:
name:
url:
version:
x-releaseDate:
The version attribute specifies the version number of the API as included in the URI (URI component <version>) according to the rules of semantic versioning.
The x-releaseDate attribute specifies the date (ISO 8601) on which the REST API was released for use. This concerns a specification extension and therefore starts with x- (see https://swagger.io/docs/specification/openapi-extensions/).
For formatting texts of attribute description, the CommonMark syntax should be used according to the OAS specification.
Rationale
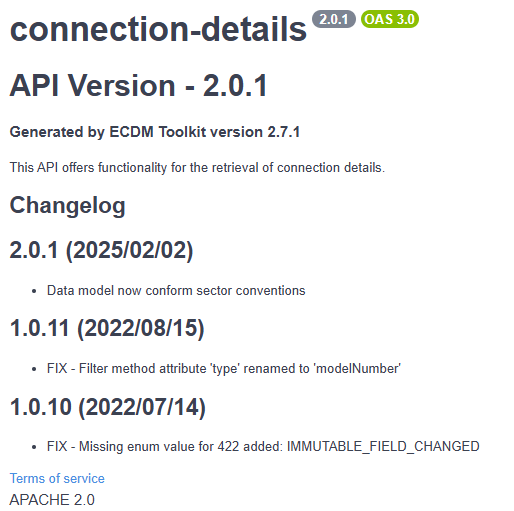
Adding this information provides context to the API for users, as can be seen by the following example.
openapi: 3.0.3
info:
title: connection-details
description: |
# API Version - 2.0.1
#### Generated by ECDM Toolkit version 2.7.1
This API offers functionality for the retrieval of connection details.
## Changelog
## 2.0.1 (2025/02/02)
* Data model now conform sector conventions
## 1.0.11 (2022/08/15)
* FIX - Filter method attribute 'type' renamed to 'modelNumber'
## 1.0.10 (2022/07/14)
* FIX - Missing enum value for 422 added: IMMUTABLE_FIELD_CHANGED
termsOfService: 'https://www.example.com/terms'
contact:
name: EDSN
email: servicdesk@edsn.nl
license:
name: APACHE 2.0
url: https://apache.org/licenses/LICENSE-2.0
version: 2.0.1
x-releaseDate: 2025-03-13
Resulting in:
Exceptions
None.
ID 08
| Title | 08 - Use of REST operations |
|---|---|
| Strategy | REST operations are used conform conventions below. |
- The GET operation in combination with a resource ID serves as the only method to retrieve a given resource.
- The GET operation without a resource ID serves as a search.
- The PUT operation serves only to replace an existing resource with a new version.
- The POST operation, if assigned to a collection, serves to create a new resource within that collection.
- The POST operation, if assigned to a ‘search’ endpoint under a collection, serves as an implementation of a complex search function (see also ID 09).
- The DELETE operation serves only to delete an existing resource (or resources).
- The PATCH operation serves only to perform a partial update of a resource.
- The HEAD operation serves to retrieve HTTP headers for a corresponding GET operation, without returning the GET response payload.
- The OPTIONS operation provides metadata about a given endpoint such as the available operations, content types and security requirements.
Open section for explanation, rationale and exception conditions
Explanation
See appendix for a detailed description of the operations mentioned.
This guideline is also available in ASNO and is explicitly added to give a more profound explanation of this design rule.
Rationale
These are the most common operations.
Exceptions
Privacy-sensitive information may not be sent in the GET URI string. Use POST if such information is sent.
ID 09
| Title | 09 - Complex search |
|---|---|
| Strategy | Use POST for extended or complex searches. |
Open section for explanation, rationale and exception conditions
Explanation
A POST may be used for an extended or complex search. There is consensus in the market for its use. To avoid conflicts, it is recommended not to implement the POST directly on a collection in this case, but on a ‘search’ endpoint under that collection (i.e. POST .../<collection-name>/search).
See appendix for a more detailed description of the POST operation.
Rationale
ASNO mentions this for geometric queries. However, allowing a POST with query parameters in the JSON body for a complex search must be seen separately from a geometry query.
Exceptions
None.
ID 10
| Title | 10 - HTTP status codes |
|---|---|
| Strategy | Define the minimum set of HTTP status codes in your API specification. |
Open section for explanation, rationale and exception conditions
Explanation
Define the minimum set of HTTP status codes that must be specified and supported by a REST API. Minimum mandatory set of HTTP status codes per REST operation:
| REST operation | 200 | 201 | 204 | 404 | 422 |
|---|---|---|---|---|---|
| GET (search) | √ | √ | √ | ||
| GET )single object) | √ | √ | |||
| PUT | opt | √ | √ | ||
| PATCH | opt | √ | √ | ||
| DELETE | opt | √ | √ | ||
| POST (create) | √ | √ | |||
| POST (search/action) | √ | √ | |||
| HEAD | √ | √ | |||
| OPTIONS | √ |
- The status code 422 is strictly used for semantic validation of the payload.
- The following mandatory codes can be seen as generic status codes and are therefore applicable to all REST operations: 401, 403, 500;
- The following optional codes can be seen as generic status codes and are therefore applicable to all REST operations: 202, 400, 429, 301, 302, 501, 503;
Opt indicates that the error code can optionally be used in special cases:
- A 204 status code can be returned for an update (PUT or PATCH) of a resource since these do not (always) return a response payload;
- A 202 status code can be returned if it concerns an asynchronous handling (PUT, POST, PATCH or DELETE);
- A 200 status code must be returned for a DELETE operation if there is a need for a response payload with information about the deleted resource.
See also appendix for a detailed explanation per operation, including the use of response codes.
Rationale
Both Geonovum and DSO describe a mandatory set of HTTP status codes that must be supported at least in an API definition. However, there are some differences visible between DSO and Geonovum in the description and application of these HTTP codes. For example, the 404 is mentioned by Geonovum, not by DSO, and we see the 412 as a mandatory code at DSO and not at Geonovum. Also in the discussions on Github of ‘Kennisplatform APIs’, we see many differences in interpretation and opinions about the correct use of HTTP status codes.
Specifying a minimum set of HTTP status codes that must be used for a REST operation gives the API designer clarity when designing and developing the REST API.
Exceptions
None.
ID 11
| Title | 11 - Use of JSON Schema Specification |
|---|---|
| Strategy | Every API call with a body must be provided with a JSON Schema Specification. |
Open section for explanation, rationale and exception conditions
Explanation
ASNO does not require the inclusion of a JSON Schema in the API (API-23). The design guideline for the energy sector does require the inclusion of a JSON Schema in the API.
Rationale
By including the JSON Schema in the API, an API call can be rejected early, already in the gateway, if the API call does not comply with the syntax. This prevents other applications from being burdened with handling syntactically invalid API calls. Including the JSON Schema also enables the API ‘user’ to validate his own messages before the implementation of the API is available.
Exceptions
None.
ID 12
| Title | 12 - Quality of Service specification |
|---|---|
| Strategy | Each API has a Quality of Service specification (QoS). |
Open section for explanation, rationale and exception conditions
Explanation
Aspects to include in the QoS:
- Integration latency;
- Opening hours;
- Availability;
- Capacity;
- Reliability.
Rationale
The API Strategy for the Dutch government does not describe a Quality of Service specification. The spec must be added as information to both the OAS specification as well as in the business service description.
For a developer who wants to connect to the interface of the API, the required information must be included in the OAS specification. Business relevant information must be included in the relevant business service description.
Exceptions
None.
ID 13
| Title | 13 - Defining date, time and date-time |
|---|---|
| Strategy | The date and time notation must be complete and unambiguous. |
Open section for explanation, rationale and exception conditions
Explanation
Date, time and date-time notation must conform to W3C DTF Note ISO 8601 [7]. This ensures unambiguous interpretation of date/time internationally.
Advice for specification of a time or a timestamp:
- Use UTC and the “Z” as time zone designator;
- Specify the time with seconds and milliseconds. If milliseconds are not known, use “000”.
Example: 2020-02-07T14:55:42.000Z or 14:55:43.000Z
Rationale
The date/time notation according to W3C DTF Note ISO 8601 [7] is defined in TC021.
Exceptions
None.
ID 14
| Title | 14 - Defining a string |
|---|---|
| Strategy | The definition of a string type must be provided with length attributes. |
Open section for explanation, rationale and exception conditions
Explanation
In line with TC028 [4], the definition of a string type in the API specification must be provided with a fixed or a minimum/maximum length attribute, where the minimum length must be 1 (the field itself may be optional). A length of 0 is therefore not allowed. Examples are:
type: string
minLength: 1
maxLength: 10
type: string
length: 10
Rationale
This is to exclude the situation where an API call contains an empty string which can therefore possibly lead to failure at service providers or service consumers.
The advice is to define the maximum length for the service consumer for strings in the response to an API call.
Exceptions
None.
ID 15
| Title | 15 - Authorization |
|---|---|
| Strategy | Authorization on APIs should be set up with OAuth2.0 and preferably with OpenID Connect. |
Open section for explanation, rationale and exception conditions
Explanation
OAuth2 is used for authorization on APIs. An Access token is used to grant access to a Resource server (API). IETF standard OAuth2
OpenID Connect is for authenticating users. OpenID Connect is a standard on top of OAuth2. However, OAuth2 does not describe how user authentication should take place. That is why OpenID Connect is recommended. IETF standard OpenID Connect
PKCE is a standard to enable the Authorization code flow for public clients. RFC
OpenID Connect and OAuth2 contain multiple flows and grant types. The following are recommended:
- Authorization code flow with PKCE when a user logs in;
- Client credentials grant for application to application authorization.
JWT access tokens are recommended to be able to do validation at Resource server (API) level without dependency on an authorization server. IETF draft JWT Access token
Rationale
Securing sensitive data within APIs is essential. OpenID Connect and OAuth2 are API security standards that are recognized and supported worldwide. By using market standards, parties that want access to APIs can easily and securely connect to them.
Exceptions
None.
ID 16
| Title | 16 - Defining field names |
|---|---|
| Strategy | Use the definition of field names as prescribed in the reference model. |
Open section for explanation, rationale and exception conditions
Explanation
Defining field names in camelCase is prescribed in guideline API-26 from ASNO. However, if the reference model used has a definition for field names, this definition prevails over guideline API-26 from ASNO.
Rationale
By using this design guideline, the definition of the field name follows the (international) standards IEC CIM and ebIX®.
Exceptions
None.
ID 17
| Title | 17 - HAL for the use of hypermedia controls |
|---|---|
| Strategy | Hypertext Application Language (HAL) is used to realize hypermedia controls. |
Open section for explanation, rationale and exception conditions
Explanation
The HAL standard is designed for building APIs in which clients navigate through resources by following (hyper)links. The HAL representation for JSON should be used if related resources (relationships) are returned as hyperlinks.
Rationale
The HAL standard for the use of hypermedia controls is laid down in the API Strategy DSO [8].
Exceptions
None.
ID 18
| Title | 18 - Expanding linked resources |
|---|---|
| Strategy | The query parameter ‘_expand’ is used to expand linked resources. |
Open section for explanation, rationale and exception conditions
Explanation
Linked resources can be loaded on request as part of a resource request (‘eager loading’). This must then be indicated via the ‘_expand’ query parameter.
Rationale
The use of the ‘_expand’ parameter for expanding linked resources is laid down in the API Strategy DSO [8].
Exceptions
None.
ID 19
| Title | 19 - Custom representation |
|---|---|
| Strategy | For targeted searches for individual fields (‘custom representation’), the ‘_fields’ parameter is used. |
Open section for explanation, rationale and exception conditions
Explanation
Users of an API do not always need the full representation (i.e. all fields) of a resource. That is why it helps if there is the possibility to select the desired fields, we call this ‘custom representation’. This can limit network traffic (relevant for lightweight applications), simplifies the use of the API and makes the output customizable (custom).
Rationale
The use of the ‘_fields’ parameter for requesting individual fields is laid down in the API Strategy DSO [8].
Exceptions
None.
ID 20
| Title | 20 - HTTP headers |
|---|---|
| Strategy | HTTP headers are used for security and adding metadata to the request and response. |
Open section for explanation, rationale and exception conditions
Explanation
HTTP headers are technical parameters that contain security information and metadata about the exchanged messages. These technical parameters can be included in the request or response headers of the messages and are not part of the functional payload of the message. The cardinality (mandatory or optional) of the HTTP headers is context-dependent and is described in the Business Service and indicated in the OAS specification. The HTTP headers are standardized according to the HTTP specification: HTTP/1.1: Header Field Definitions (w3.org) (superseded).
Rationale
The set of technical HTTP headers to be supported prescribed in the HTTP specification meets the requirements of the energy sector. The following technical parameter extensions (indicated with prefix ‘X’ according to ASNO) are added to this set:
- X-Object-ID (response): alternative for header Location if no complete URL is to be returned in the response. X-Object-ID contains the identification number of the created resource;
- X-Correlation-ID (request & response): contains a unique identifier that can be used to link different messages in a transaction;
- X-Request-ID (request & response): contains the unique identifier of the request and/or response;
- X-Sender-ID (request): the EAN13 of the market party calling the REST API;
- X-Role (request): the role of the market party indicated by the X-Sender-ID;
- X-Principal-Token (request): contains the unique identifier of the calling party (person or system) in the context of a request. How the content of the field should be interpreted exactly depends on the context; it could be an OAuth access token, for example.
Exceptions
None.
ID 21
| Title | 21 - Enumerations |
|---|---|
| Strategy | Enumerations are conditionally allowed for REST APIs. |
Open section for explanation, rationale and exception conditions
Explanation
Enumerations (enumerated types) are variable types in a dynamic or static set of allowed values:
- Dynamic set: a set that can change due to regulations, business requirements, application- or user settings;
- Static set: a set that hardly ever changes, for example all days of the week.
Enumerations are popular in API design because they are seen as a simple way to describe that dynamic or static set of allowed values. The use of enumerations is only allowed for Static sets. Dynamic sets might change at any time and thus should not be used as enumerated types in an API since changes in the range of enumerations will break any API that uses them.
If enumerations are based on an international standard (such as https://www.iso.org/iso-639-language-codes.html), then the API design must follow that notation. If enumerations are not based on an international standard, enumerations should be defined as mnemonic codes in an UPPER_SNAKE_CASE notation (in accordance with API-66 of the API Designrules Extensions [2]). Enumerations based on international standards are considered part of a Static set.
Rationale
By including enumerations in the JSON Schema, the API call can be rejected prematurely if the enumerations in the API call do not comply with the syntax.
Exceptions
The use of Dynamic sets as enumerations is not allowed in REST APIs because a change in the range of allowed values is a breaking change and forces all API clients to update to a new version. Therefore, dynamic sets should be exchanged through other means, while the permitted values are provided via an alternative mechanism - such as service design documentation.
ID 22
| Title | 22 - Use of regular personal data in the URL of REST APIs |
|---|---|
| Strategy | Regular personal data may be used in the URL of a REST API. |
Open section for explanation, rationale and exception conditions
Explanation
The privacy officers of the regional grid operators have formulated a view on the use of regular personal data in the URL of REST APIs based on the PPT of Enexis (Security & Privacy aspects in REST APIs - Enexis PPT CST integration dd. 03-06-2021).
Rationale
Privacy Aspects - Statement
Assuming that:
- When using (regular) personal data in the URL, the entire message (body and URL) is encrypted during sending;
- This data can only be viewed by the API Consumer, API Gateway and API Provider;
- Use of personal data in the URL may only be used if it is necessary for the sending and receiving parties to gain insight into this (personal) data for the performance of their task;
- No sensitive or special personal data can be derived from the URL (Category 2);
there is an acceptable risk for the Business for the use of a number of ordinary personal data in the URL of the REST APIs. In particular to make the construction of APIs manageable and controllable. This includes the use of identifying data, such as:
- BAG;
- EAN code;
- Customer number;
- Meter number;
- Postcode / house number.
A combination of certain ordinary personal data in the URL of a REST API can create new sensitive information. If the combination of ordinary personal data leads to sensitive information in the URL, this combination is not permitted!
In addition, there are a number of sensitive or special personal data that - if they become known - can cause damage to the customer. This data may never appear in the URL of REST APIs. If it is necessary to exchange this data, it will only be sent in the body, so that this data cannot be derived from logging.
The list of special personal data is exhaustive, namely:
- Race or ethnic origin;
- Political views;
- Religious or philosophical beliefs;
- Membership of a trade union;
- Genetic or biometric data;
- Health data;
- Data on sexual orientation;
- BSN number;
- Criminal data.
Sensitive data includes, for example (non-exhaustive):
- Fraud data;
- Financial data (both bank account number/credit card and payment data);
- Energy consumption data;
- Cut off data.
It is not possible for Privacy to provide an exhaustive list of personal data and to which category they belong. Whether something is personal data and the sensitivity is strongly dependent on the context in which the data is used.
Exceptions
Combining multiple regular personal data in the URL of a REST API is not allowed!
ID 23
| Title | 23 - API specification |
|---|---|
| Strategy | APIs are to be specified as OAS v3 and rendered in either JSON or YAML. |
Open section for explanation, rationale and exception conditions
Explanation
APIs are to be specified as OpenAPI Specification v3.0 or higher (OAS3). Details to be found at the OpenAPI initiative and [https://spec.openapis.org/#openapi-specification] for all specification versions. This is conform ASNO API-16 [2].
The representation format of an OpenAPI specification can be either JSON or YAML, depending on preference. Preferred format is JSON, in compliance with ASNO API-51 [2].
Rationale
The process that providers publish APIs in accordance with OAS3 leads to predictability, improved interoperability and contributes to a higher developer experience for consumers. The OAS3 standard allows for a representation in either JSON or YAML and ample tools exist to transform from one representation to the other. In compliance with ASNO, there should be at least a JSON version of the OAS3 at a standard location. However, a YAML representation is also allowed.
Exceptions
None.
ID 24
| Title | 24 - Use of xxxOf constructs |
|---|---|
| Strategy | The use of xxxOf (allOf, anyOf, oneOf) constructs in APIs should be avoided. |
Open section for explanation, rationale and exception conditions
Explanation
Although the allOf, anyOf and oneOf constructs are valid OAS3 constructs, they cause problems when generating code and importing applications.
Rationale
Various code generators and applications do not handle these constructs properly and generate incorrect code and import errors. If this is resolved in the future, it is worth considering using these constructs for the next breaking change. A market consultation must take place beforehand to check whether the market parties can handle these constructs.
Exceptions
ASNO does not explicitly mention the use of xxxOf constructs. On the github site of VNG realisatie (API working group of the Association of Dutch Municipalities), the recommendation does appear to not use xxxOf. Details can be found at the ‘Haal Centraal API design decisions’.
ID 25
| Title | 25 - Conditional access |
|---|---|
| Strategy | 1/ Choose a practical taxonomy based on the RESTful API scope; 2/ Split the resources exposed by the RESTful API into separate value objects as much as possible. Make the value object optional if not all consumers are entitled to it; 3/ Make attributes of a resource that are not part of a value object and that, depending on roles and relevance for consumers, are or are not visible, optional. |
Open section for explanation, rationale and exception conditions
Explanation
Context: A RESTful domain API provides entity E with different attribute sets. There are sets E1 and E2, which are limitedly visible. Some consumers only see E, others have access to E + E1, E + E2, or all attributes (E + E1 + E2).
Security of RESTful APIs is normally set up over the endpoints (the URLs). However, in the context described above, this is not sufficient to reliably unlock the information on that endpoint. After all, multiple consumers with different roles call the same endpoint and must receive customized information in return.
Assumptions:
- The taxonomy of the information model is leading. One API may possibly provide multiple specializations of resources if this leads to a better interface (see example below);
- Each entity (resource) is uniquely addressed by exactly one endpoint. The URL of this endpoint is the unique identification of the resource;
- A subresource is defined in the context of the API as a separate entity that is inseparably linked to a parent resource and can only be addressed via that parent resource. A subresource must contain a unique identifier (e.g. the counter of a meter can be seen as a subresource of that meter with the OBIS code as identification). The taxonomy of the information model of the API determines whether subresources appear as such in the API and if so they are considered as ‘normal’ resources with all associated rules for disclosure. A subresource always has its own endpoint within the API (in the context of the resource that owns it, e.g. smart-meters/{id}/registers/{obis-code}
- A value object is defined in the context of the API as a group of attributes that together have a semantic meaning, but do not have their own identity (see a value object as a composite attribute of the resource, e.g. an address). A value object is generally manipulated as part of the resource. A value object can only be accessed in the context of the resource that owns it, e.g. customers/{id}/billing-address
- The roles of the customer are leading for determining the information to be returned and changes to this should have no (or as little as possible) impact on the schema of the API;
- The schema information within the API contract is not necessarily unambiguous for all the different roles (because this is a static schema) and it is therefore up to the customer to derive the information relevant to him from the schema documentation;
- The customer always gets the maximum information back that ‘fits’ his permissions, there is no other filtering (unless explicitly included in the design of the API, e.g. filter parameters in search queries);
- The scope of a domain API is a single domain. That is: the API does not provide information from other domains, other than a reference to the resource(s) that can provide that information;
Rationale
Ad 1: A good taxonomy can solve some of the problems, especially if customers with different roles are involved in separate parts of that taxonomy (e.g. large-scale consumer connections, small-scale consumer connections). This results in multiple logical endpoints with possibly separate target groups per endpoint.
Ad 2: When drawing up the schema, it is examined per resource whether the resource can be divided into separate components (‘value objects’) whose attributes together have a semantic meaning (e.g. address). The objective of this division is that customers receive complete value objects so that the cardinality of attributes within the value object does not depend on permissions and/or roles. A value object that is not permitted for all roles must be made optional.
Ad 3: It will never be entirely possible to build a given resource entirely from value objects. There will therefore be ‘left over’ attributes within the resource. Some attributes will have to be optional, because they are mandatory for one customer and prohibited for another.
The chosen solution is a compromise between maintainability, clarity and predictability of the API. There are disadvantages to the chosen solution, especially when it comes to predictability towards the receiver. A receiver cannot deduce from the API schema whether a non-received attribute is the result of a lack of rights or not being filled in this attribute. For this, he is dependent on the quality of the service documentation.
However, an implementation in which the schema is a reflection of the permissions and roles of all possible consumers, actually only makes the problem more complex and makes both the API and the underlying models fragile and difficult to maintain.
Example omitted
Exceptions
The proposed solution applies to RESTFul domain APIs. For APIs that expose analytical data products, different rules apply as they will often use other standards such as SPARQL or OData;
ID 26
| Title | 26 - Use encoded cursor paging |
|---|---|
| Strategy | If an operation uses pagination, this is implemented using an encoded cursor pagination algorithm. |
Open section for explanation, rationale and exception conditions
Explanation
Encoded cursor pagination works on the principle that an opaque string (preferably Base64 encoded) is always returned (for the client), regardless of the pagination implementation on the server side. The client must provide this cursor with a subsequent request to obtain a subsequent set of data. This subsequent request must be submitted within a reasonable period of time (maximum 5 minutes). If the same cursor is (re)used after a longer period of time, it is possible that different results will be returned, e.g. as a result of adding or removing records.
The client sends the following query parameters:
| Query parameter | Meaning |
|---|---|
| _cursor | Optionally a cursor received from the server from a previous response. The first time this will of course be missing. The client must return a received cursor string without modifications and a cursor has a (very) limited validity (depending on the dynamics of the dataset used, but max. 5 minutes). |
| _limit | Optionally the number of records per page. In principle this is a constant value. If no limit is given, the server should use a realistic default of 100. A limit of 100 means that there are at most 100 records in a page. |
The server will then return the following data in the body of the response:
| Property | Meaning |
|---|---|
| nextCursor | Cursor of the next page, absent if there is no next page. |
| items | An array with records. The array will contain a maximum of ‘limit’ number of records. Instead of ‘items’ a more appealing name can also be chosen, depending on the type of records that are returned. |
Rationale
Development teams are free to choose the most efficient method of pagination for the implementation in question, without the client having to know about it. Encoded cursor pagination does not enforce the implementation of a certain style of pagination. This promotes consistency within APIs and also makes the implementation on the client side unambiguous.
A disadvantage of encoded cursor pagination is that it is no longer possible to navigate directly to a specific page. With offset pagination, it is possible to navigate directly to offset=100000&limit=100, for example. This is not possible with encoded cursor pagination. The same applies to backward navigation. However, the use cases for this do not seem to exist at the moment.
Exceptions
APIs that do not currently use encoded cursor pagination will remain permitted for the time being. New APIs to be delivered are expected to use encoded cursor pagination.
ID 27
| Title | 27 - Use simple search to retrieve a resource via a foreign key |
|---|---|
| Strategy | If a resource has to be retrieved using a foreign key (i.e. a key that is not the primary key of the resource), use GET on the resource collection and provide the key as a query parameter. |
Open section for explanation, rationale and exception conditions
Explanation
A resource has to be retrieved using a key that is not the primary key of the resource, but is available as a property in the resource collection. In this case, it is not feasible to use the key as a path parameter since those are reserved for primary resource keys. The solution is to implement a simple search on the collection, using the foreign key as a query parameter.
Example: GET .../meter-management/v1/meters?accounting-point={EAN18}
In the example above, a meter is selected from the collection of meters using the associated accounting point as the (foreign) key.
Rationale
A resource is typically retrieved using the primary key of that resource within a collection of resources of equal type. When a foreign key is used, this can not be specified as a path parameter since it addresses a different type of resource. Creating an ‘artificial’ collection just to be able to use the foreign key as a path parameter typically leads to a confusing API structure as shown in the example below.
Example: GET ...meter-management/v1/accounting-points/{EAN18}
In the example above, an artificial collection has been defined with no other purpose than to retrieve a meter using the (foreign) key of the associated accounting point. However, this endpoint suggests that the meter-management API contains a collection of accounting points, which is not true.
As an alternative, one could create separate endpoints for each foreign key as shown in this example:
Example: GET ...meter-management/v1/meters-by-accounting-point/{EAN18}
The above example leads to a RESTful API that is cluttered with endpoints that distract from the primary function of the API and which are also not addressing real resources, which is against the principles of RESTful API design.
Exceptions
None.
Comments, suggestions and improvements can be issued via a ticket. Thank you.
-
Where this document refers to APIs, we mean REST APIs. ↩
-
Referred documents can be found in the global document reference. ↩